Cosa vi viene in mente se sentite parlare di archivi storici? Faldoni polverosi e documenti noiosi? Vi sbagliate! Gli archivi storici possono diventare frammenti di un affascinante romanzo - il nostro - perché contengono storie di persone e di luoghi. Ma come rendere queste storie accessibili?
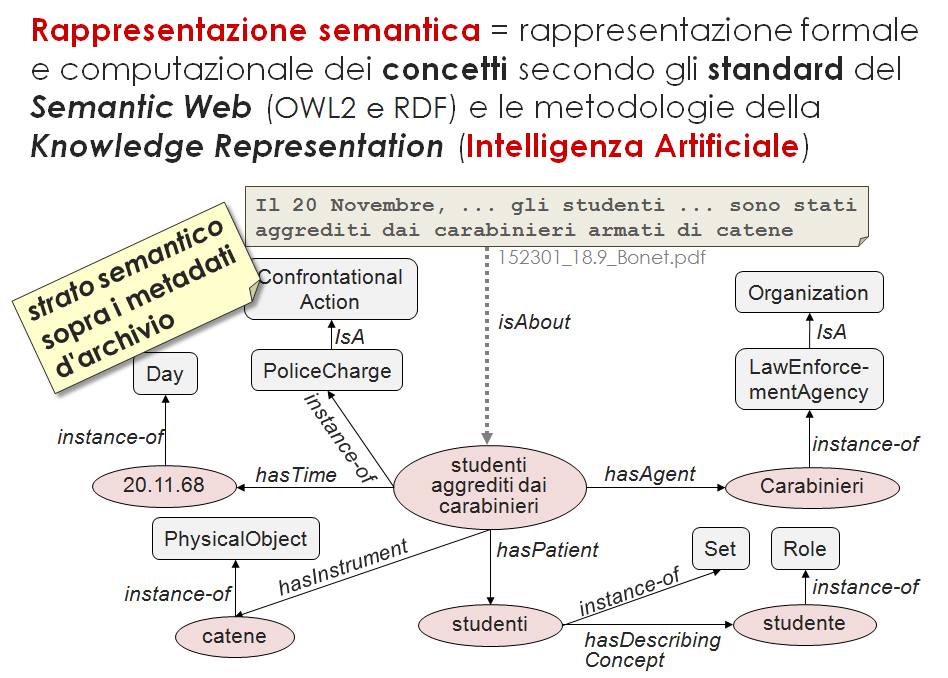
L'idea è quella di costruire un sistema "intelligente", che - allo stesso modo di un archivista - sappia di cosa parlano i documenti. Questo è possibile dotando il sistema di accesso agli archivi di uno "strato semantico" che rappresenta il contenuto delle risorse dell'archivio stesso, mettendo così il sistema in grado di offrire al pubblico un accesso ai documenti efficace e flessibile.
Facciamo un esempio. Ernesto è un giovane storico alla ricerca di documenti originali che parlano delle azioni violente perpetrate dalle forze dell'ordine nel '68. Immaginiamo che Ernesto utilizzi un classico motore di ricerca e che ricerchi parole chiave come carica, scontri, polizia, carabinieri. Il sistema troverà un insieme di documenti (fig. 1) - articoli, immagini, volantini - che contengono quelle parole o che sono stati taggati con esse (eventualmente anche documenti che parlano di "cariche" dello stato o di "scontri" politici e che non riguardano direttamente la ricerca di Ernesto).
Immaginiamo ora che il sistema sia dotato dello strato semantico (fig. 2) di cui abbiamo parlato. Ernesto può ora ricercare utilizzando concetti: azioni conflittuali violente compiute dalle forze dell'ordine. Il sistema, esattamente come un archivista esperto, proporrà a Ernesto un insieme di risorse più ricco e preciso (fig. 3), che comprende documenti pertinenti, anche se non contengono le parole ricercate, o altre risorse (fig. 4) il cui testo è rovinato e in cui, quindi, la ricerca testuale è impossibile.
Ma come si fa a costruire lo strato semantico? A questa domanda prova a dare una risposta PRiSMHA (Providing Rich Semantic Metadata for Historical Archives), il progetto (2017-2020) che coordino e che coinvolge i Dipartimenti di Informatica e Studi Storici (fig. 5). L'idea alla base di PRiSMHA -svolto in collaborazione con la Fondazione Istituto piemontese Antonio Gramsci (Polo del '900) e finanziato da Compagnia di San Paolo e Università di Torino - è che lo strato semantico possa essere costruito grazie alla sinergia tra due approcci:
• Crowdsourcing: piattaforma partecipativa online in cui gli utenti collaborano alla costruzione dello strato semantico.
• Information Extraction: approccio dell'Intelligenza Artificiale che estrae automaticamente dai testi informazioni rilevanti (luoghi, persone, eventi), per fornire suggerimenti utili agli utenti della piattaforma collaborativa.
Il progetto si fonda sul dialogo interdisciplinare tra informatici, storici e archivisti, nonché sulla collaborazione tra Università e istituti culturali.
A oggi è stato sviluppato un prototipo di piattaforma collaborativa, affiancato dalla sperimentazione di tecniche di Information Extraction sui documenti testuali disponibili.
Inoltre sarà possibile costruire applicazioni quali guide turistiche, strumenti educativi, servizi ai cittadini che utilizzano direttamente le informazioni su eventi, persone, luoghi di cui parlano i documenti d'archivio presenti nello strato semantico costruito da PRiSMHA, grazie a tecnologie standard quali servizi REST (cioè servizi online alle cui funzionalità un’applicazione può accedere automaticamente attraverso richieste standardizzate basate sul "protocollo" REST) e SPARQL endpoint (cioè applicazioni web che, attraverso il linguaggio di interrogazione SPARQL, permettono di accedere a base di dati semantiche).